
概要
音声データをRVCを使って変換します。
声質は元となる音声データにかなり依存します。一方で声色(誰の声かということ)は学習データに依存します。
今回はニック・バレンタインのセリフを違う声にしてみます。
必要なもの
- LazyVoiceFinder
- RVC WebUI
- Yakitori Audio Converter
RVC WebUIを準備する
RVCはRetrieval-based-Voice-Conversionの略です。これをブラウザを通して操作するものがRVC WebUIになるようです。公式サイトはおそらくこちらです。
ダウンロード
GitHubなのでかなりわかりにくいと思いますので、補足しておきます。
公式サイトを開き、右側のReleasesのところをクリックします。
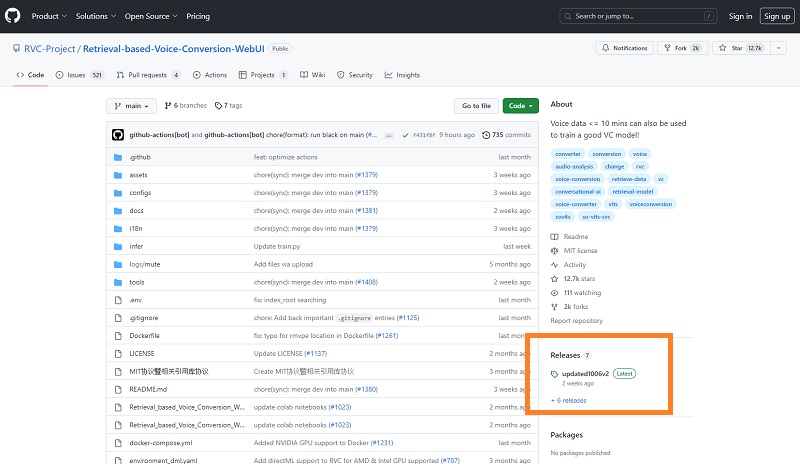
Releaseが7つあり、最新版がupdated1006v2であり、2週間前にリリースされた、ということがわかります。Releasesをクリックしてから次のページで一番上を選びます。あるいはupdated1006v2をクリックすると自動的に一番上に飛びます。
その先のページではオレンジ色で囲った枠のリンクから、自分のPCで使用しているグラフィックカードに合った方を選びます。Nvidia GeForceなら上で、AMDまたはIntelなら下になります。
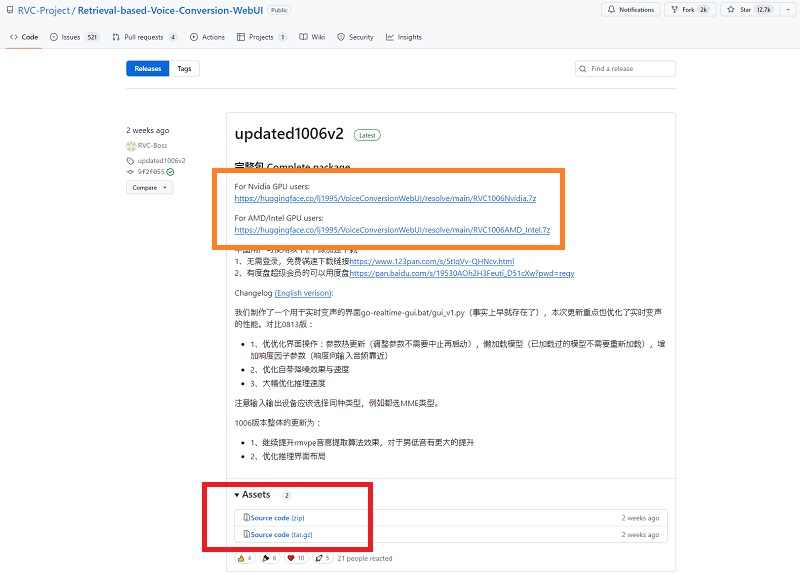
ファイルサイズが5GB以上もあるので、ディスクの空きや回線状況など備えた上でダウンロードします。
ちなみに下にある赤色で囲った枠はソースコードであり、自分でアプリをビルドする際に必要なものですので、今回は不要です。
おそらくはサイズが大きすぎるので外部のサイトに置いてあるから別リンクを貼っているのでしょう。
展開
7zipなので扱えるアーカイバを用意します。Fallout 4プレイヤーにとってはいまさらでしょうが。
展開に相当時間がかかり、展開後のサイズは15GBほどになるのでディスクの空きに注意してください。
起動
go-web.batをダブルクリックで起動です。
コマンドプロンプトが開いてからブラウザが開きます。以降はブラウザで操作します。
コマンドプロンプトは動作状況が確認できるログビューワとしても機能します。バックグラウンドで動作するプロセスになりますので閉じてはいけません。
試しに変換してみる
何でもいいのでwavファイルを1つ用意します。
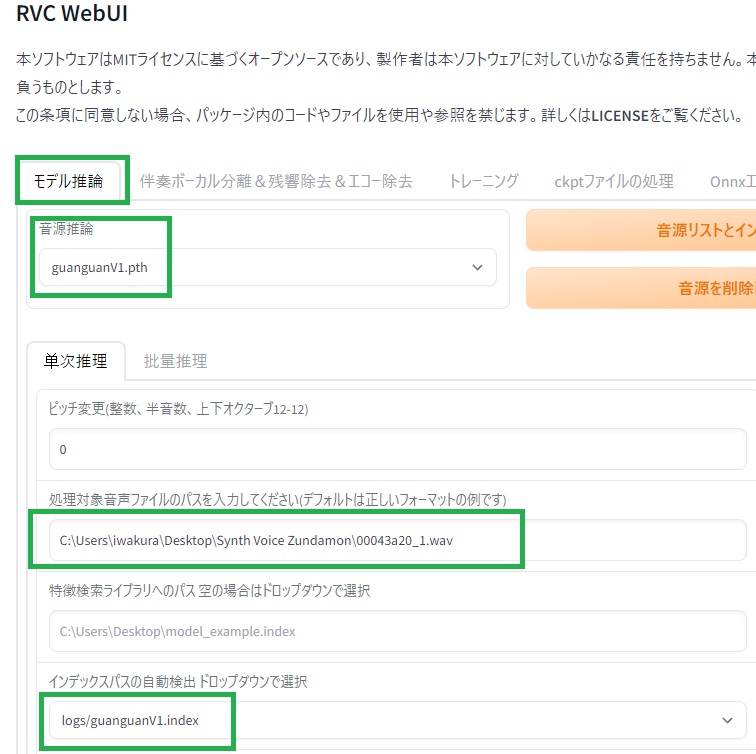
モデル推論タブを選択します。
音源推論に4つほどあるようなので、どれでもいいので選びます。
単次推理タブを選択します。単次が1個のファイルで批量が複数のファイルでしょうか。単は中国語のようで微妙に違いますが気にしないでください。
処理対象音声ファイルのパスを入力してくださいのところで用意したwavファイルのパスを入力します。
インデックスパスの自動検出の部分はよくわかりませんが、音源推論と同じ名前のものを選ぶといいのだと思います。選ばないと自動的に同じ名前のものを選んでくれるのかなと思います。
あとは変換ボタンをクリックしてから再生ボタンで聴けるはずです。

学習させる
音声データを用意する
音声データが既に用意できているなら、この手順はスキップできます。
LazyVoiceFinderを起動します。
Fallout 4モードにして、Fallout4.esmを開きます。
Voice Typeで声を絞り込みます。例えば女の子供の声ならFemaleChildです。
セリフを全部選択します。
右クリックして「選択行のファイルをエクスポート」を選択します。
LazyVoiceFinderのexportフォルダ以下にfuzファイルが展開されます。
Yakitori Audio Converterを起動します。
上記フォルダを指定します。
fuz形式からwav形式に変換します。
fuzファイルとlipファイルは余分なので削除するか移動しておきます。
全てのwavファイルを選択して右クリック、プロパティで詳細を見ると合計再生時間を確認できます。後述する総エポック数を決めるのに重要になってきます。
RVCに学習させる
トレーニングタブを選択します。
モデル名に名前を決めて入力します。
モデルに音高ガイドがあるかどうかはtrueにします。おそらくfalseでも影響ないようですが、念のためtrueにします。
ステップ2aのところで、トレーニング用フォルダのパスを入力してくださいに用意した音声データのパスを入力します。
データ処理をクリックすると学習が始まります。おそらく end preprocess と出たら完了です。コマンドプロンプトの方が見やすいです。
ステップ2bで特徴抽出をクリックします。これは要らないように見えるのですが、やらないと次の作業でエラーになってしまいます。声の高音部分の発音も良くなるのだとか。
ステップ3でチューニングを行います。重要なのが総エポック数で、合計再生時間 x 総エポック数が500分を目安にするのが良いらしいです。
モデルのトレーニングをクリックします。相当時間がかかります。1時間前後でしょうか。おそらく Training is done. The program is closed. と出たら完了です。
特徴インデックスのトレーニングをクリックします。こちらは added_***_v2.index と出たら完了です。
ワンクリックトレーニングは、上記のボタンクリックの作業をまとめて一気に行うようです。
確認する
モデル推論タブに戻ります。
音源リストとインデックスパスの更新をクリックします。
音源推論に作ったものが追加されているはずなので、あとは同じです。
一括変換する
批量推理に切り替えます。
ピッチ変更は同性なら0、男性から女性は12、女性から男性は-12がよいらしいです。
入力ソースの音量エンベロープと出力音量エンベロープの融合率は、おそらく音量を学習データ側重視か変換に使うデータ側を重視か、でしょうか。デフォルトの1のままにしました。
検索特徴率は1に近づけるほどこもるような、平坦な感じになる印象です。0に近い方がいいでしょうか。
エクスポート形式はwavにします。
出力されるファイルのファイル名が ****.wav.wav となってしまうので、なんとかして元に戻します。
Yakitori Audio Converterでfuz形式に変換します。lipファイルを含めるようにする設定を忘れないようにします。
おわりに
Skyrimで人気のRabi Follower_Japanese Custom Voiceから音声データを取り出して学習させてみました。声はナユキユズという方です。
予想以上にしっかりとRabiの声になるのが面白いです。ただし、ニックの声は演技に年配の男性の訛りがあり、それがしっかり引き継がれるため、違和感もあります。変換前の声が同性だと違和感も減るのだと思います。
色々と応用できそうです。
- 女主人公の声を学習させて、Modで追加されるフルボイスの英語のセリフを自分で吹き替えるかVOICEVOX等で話させて、女主人公の声に変換する。
- 子供の女の子の声を学習させて、レイダーの女の声を変換して、子供版レイダーの声を用意する。
DepravityのMurphyの日本語訳のテキストをVOICEVOXにて四国めたんに話させ、RVCにMurphyの声を学習させて変換してみましたが、プレイには十分といえる品質の日本語音声を用意できました。
